
티스토리 뷰
후기쓰고 바로 복습내용 조지러왔습니다

원래 복습내용을 쓰려고 하지는 않았는데 이런 컴퓨터 수업은 복습이 애매해서 나름의 방법을 찾았음
1. 수업 내용 목차 정리하기
2. 실습해보기
사실 ㅈㄴ 별거 없는데 있는척 해봤습니다
실습을 해볼건데 에이블스쿨에서 실습파일도 줍니다 물론 주지만 저는 초절정 잉여 백수 울트라 쌀벌레 취준생이기 때문에 주말에 심심해서 새로운 아이디어를 가져왔죠 ...ㅋㅋㅎ 바로바로...! <내가 실습파일 만들어 보기> 입니다. 사실 이걸 기획한건 지하철에서 무슨 동기부여 영상을보는 아저씨 휴대폰을 훔쳐보다가 아이디어를 얻었습니다. 대충 복습은 보면서 하는게 아니라 눈가리고 하는거다~ 라는 내용이었습니다 그래서 눈감고 코딩을 할수는 없으니 목차만 보고 똑같이 만들어 보는거죠

너무 하고싶어서 간식국룰 이삭토스트도 패스하고 집에 들어와서 실습파일 만들기를 해보려고 했으나 문제가 바로 생겼습니다. 바로 강사님은 데이터를 잘 만들어서 가지고 계신데 비해 저는 그런게 없다는 겁니다 ㅅㅂ
제가 가진 데이터라고는 밈과 움짤 그리고 술약속 뿐인데 어떻게 하라는 걸까요? 그래서 정보의 바다를 뒤져 데이터를 만드는 법을 가져왔습니다.
바로바로 웹 스크래핑입니다 근데 이게 수업때 배운것 보다 더 어렵더라고요? 그래서 이번 주말은 친구없이 카페가서 이걸로 때우면 세상 내가 제일 재밌겠다 싶어서 시작했습니다. 일단 함 보시죠 근데 저는 틀릴가능성이 높습니다 그냥 궁금한 사람만 보세요 (책임없는 쾌락)
일단 이걸 하려면 requests 랑 BeatifulSoup이라는 모듈을 써야됩니다
requests는 웹에있는 데이터를 html을 텍스트 형태로 가져온거고 거기에서 필요한 정보만 쏙쏙 칸쵸먹는 저마냥 뽑아오는게 뷰티풀스프이랍니다.
pip install beautifulsoup4 이걸로 터미널에서 깔고~
일단 url을 받아서 테이블에 있는 정보를 받아오는 함수를 만들겁니다. 받을정보는 프리미어리그 득점순위입니다 ㅋㅋㅋ 써먹을 곳이 있을까 싶지만 그냥 받아오는거죠
함수명은 player_stats로 하겠습니다.
import os
import requests
from bs4 import BeautifulSoup
import csv
def epl_player_stats (url):
# url 에서 response 받아서 soup만들기
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
#테이블에서 행 (전체로 해야함) 찾기
table = soup.find('table')
rows = table.find_all('tr')
#빈 리스트 만들기
player_stats = []
# 각 행을 반복하여 데이터를 추출합니다. (이름, 클럽, 국적, 골 수)
for row in rows[1:]: # 첫 번째 행은 헤더이므로 스킵합니다.
columns = row.find_all('td')
player_name = columns[1].text.strip()
club = columns[2].text.strip()
nationality = columns[3].text.strip()
goals = columns[4].text.strip()
player_stat = {
'Player Name': player_name,
'Club': club,
'Nationality': nationality,
'Goals': goals
}
player_stats.append(player_stat)
return player_stats
def save_to_csv(player_stats, filename):
# 데이터를 CSV 파일로 저장합니다.
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['Player Name', 'Club', 'Nationality', 'Goals']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for player in player_stats:
writer.writerow(player)
if __name__ == "__main__":
url = 'https://www.premierleague.com/stats/top/players/goals?se=578'
player_stats = epl_player_stats(url)
filename = 'premier_league_top_scorers.csv'
save_to_csv(player_stats, filename)
print("CSV 파일이 성공적으로 생성되었습니다.")
print("파일 경로:", os.path.abspath(filename))이렇게 만들고 나니까 홈페이지에 첫 화면만 스크랩 되더군요 흑흑 자동으로 버튼눌러서 전부다 스크랩 하려면 저에게는 난이도가 높은것 같아서 어찌할지 고민이 참 많았습니다

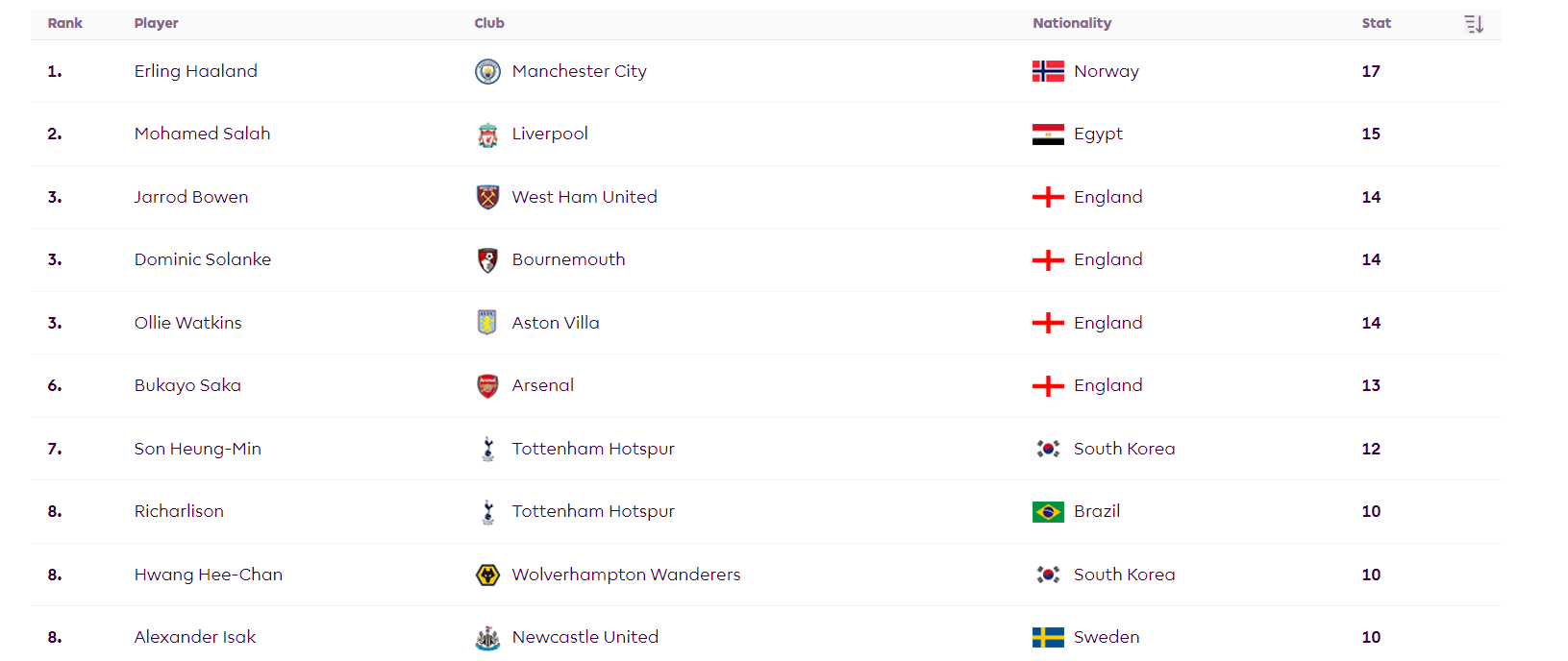
ㄷㄷ 성공할줄 몰랐는데 시간을 갈아넣으니 성공했군요!
근데 노가다로 버튼눌러서 다 수집하기에는 벅찰거 같아서 일단 도전해 보았습니다
첫 저의 잔꾀는 만약 버튼을 눌러서 url끝에 숫자가 있는데 그게 바뀌면 반복문으로 해볼까 했지만 버튼 누른다고 url이 바뀌지는 않습니다... 그냥 초딩같은 생각이었죠
그래서 구글링 그냥 했습니다. xpath라는게 있더군요 일단 문제의 그 버튼 xpath를 찾았습니다. 그냥 ctrl +shift+c하고 그 버튼 누르면 나옵니다 //*[@id="mainContent"]/div[2]/div[1]/div[2]/div[2]
일단 from selenium import webdriver 요놈을 임포트해서 써야한답니다.
.
.
.
저는 해봤는데 실패했습니다
근데 아주 좋은 소식이 있는데요 바로 에이블 스쿨에서 웹크롤링강의가 있더라고요 ㅋㅋㅋ
아 ㅋㅋ 꼬우면 에이블스쿨하던가~
그래서 그때 배워서 다시 도전하고 (뭔가 구글에 코드 많이 있는데 배워서 하는게 좋을거 같음)
일단은 네이버 스포츠 에서 정보를 가져오겠습니다.
import os
import requests
from bs4 import BeautifulSoup
import csv
def epl_player_stats (url):
# url 에서 response 받아서 soup만들기
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
#테이블에서 행 (전체로 해야함) 찾기
table = soup.find('table')
rows = table.find_all('tr')
#빈 리스트 만들기
player_stats = []
# 각 행을 반복하여 데이터를 추출합니다. (이름, 클럽, 국적, 골 수)
for row in rows[1:]: # 첫 번째 행은 헤더이므로 스킵합니다.
columns = row.find_all('td')
player_name = columns[1].text.strip()
goals = columns[2].text.strip()
assists = columns[3].text.strip()
shoots = columns[5].text.strip()
shoots_on_target = columns[12].text.strip()
fouls = columns[6].text.strip()
corners = columns[9].text.strip()
penalties = columns[10].text.strip()
games = columns[13].text.strip()
player_stat = {
'Player Name': player_name,
'Goals': goals,
'Assists' : assists,
'Shoots' : shoots,
'S_on_t' : shoots_on_target,
'Fouls' : fouls,
'Corners' : corners,
'Penalties' : penalties,
'Games' : games,
}
player_stats.append(player_stat)
return player_stats
def save_to_csv(player_stats, filename):
# 데이터를 CSV 파일로 저장합니다.
with open(filename, 'w', newline='', encoding='utf-16') as csvfile:
fieldnames = ['Player Name', 'Goals', 'Assists', 'Shoots', 'S_on_t','Fouls','Corners','Penalties','Games']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, delimiter='\t') # 구분자를 탭으로 설정합니다.
writer.writeheader()
for player in player_stats:
writer.writerow(player)
if __name__ == "__main__":
url = 'https://sports.news.naver.com/wfootball/record/index?category=epl&year=2023&tab=player'
player_stats = epl_player_stats(url)
filename = '2023_premier_league_top_scorers.csv'
save_to_csv(player_stats, filename)
print("CSV 파일이 성공적으로 생성되었습니다.")
print("파일 경로:", os.path.abspath(filename))
이걸로 성공!
자 이게 준비과정이었는데요 너무 어렵습니다 저녁먹고 다시 ㄱㄱ할게요
'주절주절 일상' 카테고리의 다른 글
| 아무것도 안하고 놀고 자고 먹은 사람의 반성문 (0) | 2024.05.24 |
|---|---|
| 싸피(SSAFY) 12기 모집설명회 후기 (번뇌... 후회... 그리고 반성...) (0) | 2024.05.03 |
| 주절주절주절주절 (0) | 2024.04.23 |
| KT 에이블스쿨 8주차 후기 (0) | 2024.04.18 |
| KT 에이블스쿨 1주차 후기 (0) | 2024.03.02 |